使用osquery进行系统监控和系统数据收集
0. 前言
系统的实时监控系统,在技术上的选择并不少,比如商业的New Relic,或者开源的collectd配合InfluxDB+Grafana,都可以快捷迅速地解决需求。
本文介绍另外一种可能性,即osquery,它是facebook开源的一个项目,它将操作系统的各类资源看作一个RDBMS,允许开发者或者运维人员使用类SQL语言去查询系统数据。每一类系统资源都被抽象成一个有名数据库表,比如进程、已加载的内核模块、活动的网络链接、浏览器插件甚至硬件设备事件。
第一篇文章作为入门教程,仅介绍安装和基本使用。
1. 安装
对于各类Linux发行版以及OSX,osquery已经有了直接的二进制安装包,直接使用包管理器进行安装即可。另外OSX在homebrew中也已经发布,可以直接使用brew进行安装。
下面介绍一下Linux下从源码编译安装的方法。
首先是osquery的源代码,可以从github获取:
git clone https://github.com/facebook/osquery.git 然后根据官方文档,直接make deps会有问题,是因为thrift没有安装,找不到相应的库。
于是需要先安装同样出自Facebook的thrift,它是一个跨语言的服务框架,可以通过接口定义语言(IDL),生成不同语言的服务器和客户端接口,开发者在其基础上就可以轻松编写一个跨语言的网络服务了。thrift的源代码可以从apache的相关页面获取:
https://thrift.apache.org/download 同样是编译安装,首先安装依赖包和C++语言支持(需要boost):
sudo apt-get install libboost1.55-all-dev g++ flex bison autoconf automake libtool pkg-config 如果需要java语言支持,那么还需要ant、maven以及JDK,还需要配置好相应的环境变量。
如果需要python语言支持,那么还需要python2.6以上的环境、pip以及python-dev软件包(包含开发头文件)。
如果需要ruby语言支持,那么还需要gem和bundler包管理器。
其他语言支持具体的需求可以参考thrift的官方页面。
然后进入到thrift的源码目录,使用configure命令进行编译配置,此时可以用with-XXX或者without-XXX来制定相关语言的支持。值得说明的是,0.9.2版本的thrift的单元测试有问题,某些测试需要的三方资源并没有出现在相应目录里面,所以直接make会出现单测错误编译失败的情况。只要在configure的时候加入–without-tests参数跳过单测即可。
然后就可以编译并安装:
make
make install然后在默认配置下,thrift相关的库就已经在/usr/local/lib中了。
这时候回到osquery的目录,执行cmake . && make deps,就会下载并编译其他依赖。值得说明的是,依赖库都在amazon的aws上,由于GFW的原因下载经常会断线,所以还是配置好一个可以顺利X墙的梯子。
另外,在默认情况下,osquery编译的时候会到/usr/local/lib中找thrift相关的库,如果你没有把thrift安装到这里,那么需要配置THRIFT_HOME的环境变量。
然后make && make install,泡杯咖啡等着编译完毕即可。
2. osquery的使用
如前言中所描述,osquery将计算机资源抽象成了数据库表,这些数据库表都是通过其内置的插件和API实现的。其中许多操作系统的内置资源抽象已经写好了,直接使用即可。下面看几个例子:
首先用osqueryi命令进入解释器模式。
列出当前操作系统中所有的用户:
SELECT * FROM users; 运行结果:
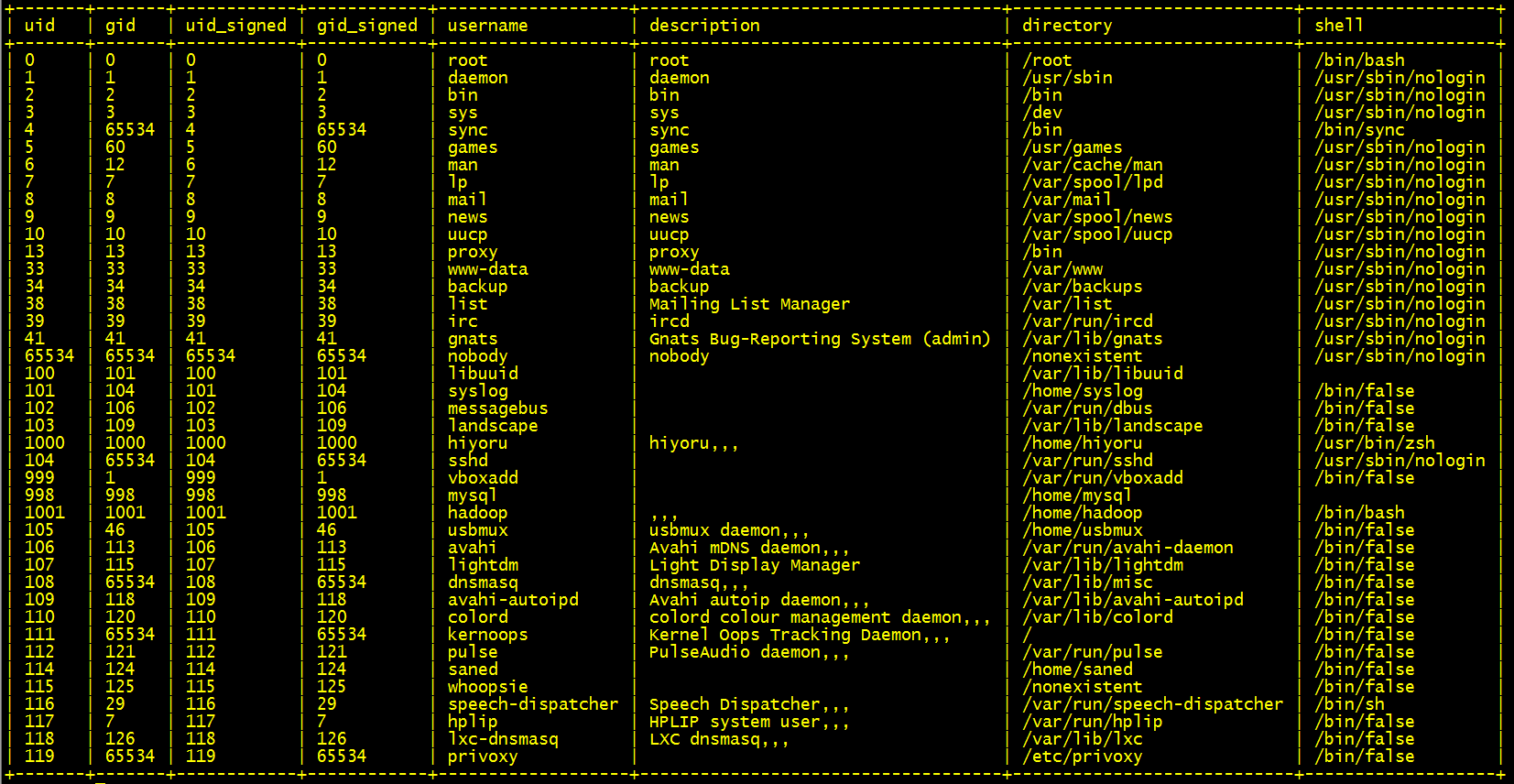
列出所有进程:
SELECT pid, name, cmdline FROM processes; 运行结果:
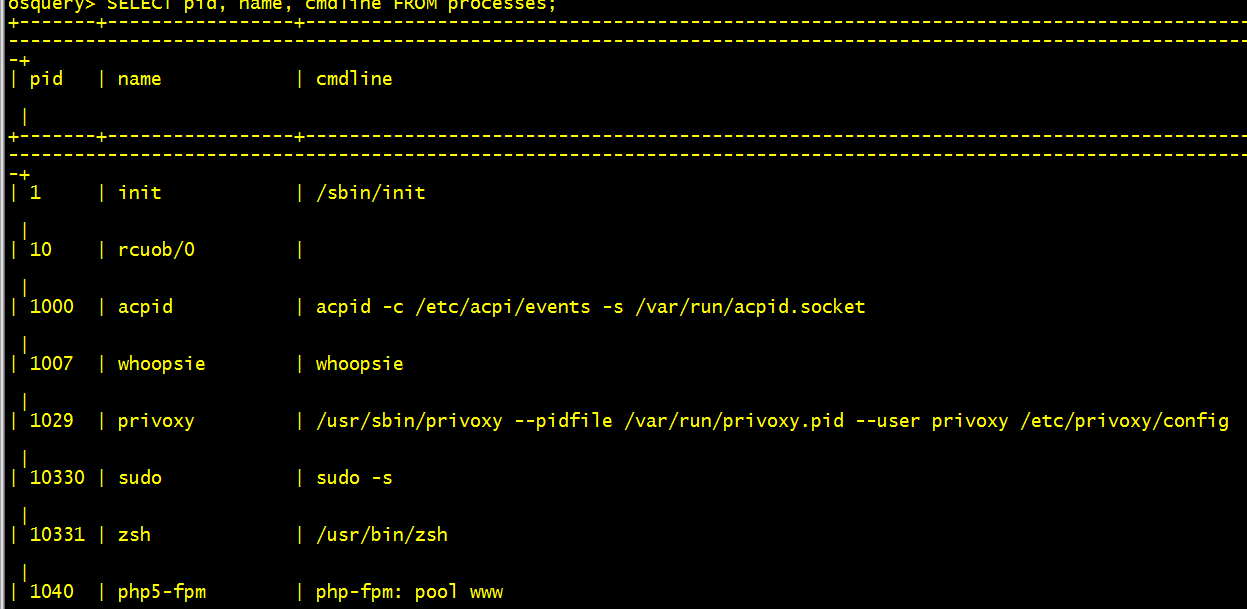
取得当前的进程名、PID以及该进程使用的端口:
SELECT
DISTINCT process.name, listening.port, process.pid
FROM
processes AS process
JOIN
listening_ports AS listening
ON
process.pid = listening.pid
WHERE
listening.address = '0.0.0.0';取得当前系统中所有进程的打开文件的数量:
SELECT
DISTINCT process.name, process.pid, count(f.path) as file_count
FROM
processes AS process
JOIN
process_open_files f
ON
process.pid = f.pid
GROUP BY
process.name,
process.pid;运行结果:
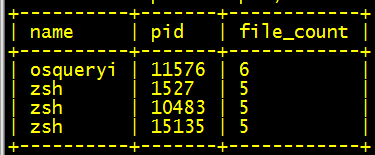
获取到可能异常的ARP请求(广播的mac地址数量大于1):
SELECT
address, mac, count(mac) AS mac_count
FROM
arp_cache
GROUP BY
mac
HAVING
count(mac) > 1;可以看出,osquery的使用极大地依赖table。具体其内置的table说明,可以参看官方文档。至于怎么编写一个plugin支持新的table,后续的文章将会介绍。
3. 对比
对比collectd,osquery最大的优势,就是不需要再去关心那些系统数据收集所以来的软件库了,一切都已经由插件帮我们做好,只需要用SQL语句就能轻松查看并且收集到系统的运行数据。
另一方面,osquery目前还没有Grafana这样出色的前端来进行数据可视化的配合,collectd诸多功能强大的插件也是osquery所不具备的,整合成真正方便可用的产品,osquery还有路需要走。
4. 参考资料
[1] https://github.com/facebook/osquery
[2] https://osquery.io/docs
[3] http://osquery.readthedocs.org/en/stable/development/building/
[4] https://thrift.apache.org/
-EOF-